
Apache Hadoop is one of the leading solutions for distributed data analytics and data storage. Apache Hadoop has gained momentum over the past few years as the open-source platform to collect, store and analyze various types of data. Apache Hadoop addresses the complete needs of data-at-rest, powers real-time customer applications and delivers robust big data analytics that accelerate decision making and innovation through a strong ecosystem:
- HDFS: a distributed storage layer
- YARN: a resource negotiator
- MapReduce: a distributed framework
- Spark: a distributed framework, in-memory
- PIG, HIVE: query based processing of data services
- HBase: a NoSQL database
- Mahout, Spark MLLib: two machine learning algorithm libraries
- Solar, Lucene: search and index solutions
- Zookeeper: managing cluster frameworks
- Oozie: job scheduling
- Rancher: access management
- And many others: Drill, Impala, Gobblin, HAWQ…
Many datalakes have been built using Apache Hadoop. As a central data platform, a datalake has to quickly and easily deliver data insights to businesses and their customers. It has to keep the technologies involved in processing the data up-to-date, be compatible with the cloud strategy, and strongly embraces data practices. As our clients need more and more data capabilities, their datalakes should be agile, modern, and future-proof way to meet today’s demands and implement effective ways to leverage data.
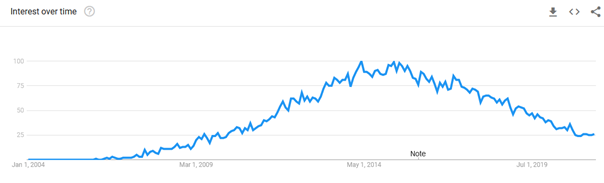
Google Trends shows how interest in Hadoop reached its peak popularity from 2014 to 2017. After that, we observe a distinct reduction in Hadoop searches.
In this article, we will discuss why and how to move from Apache Hadoop on-premise to rapidly evolving technologies like Kubernetes and BDaaS Platforms.
Why Move from Hadoop?
Complexity and ROI
The Apache Hadoop platform is a complex stack, with many sensible components (Zookeeper and HDFS in the top). Teams can hardly focus on the delivery and spend too much time on the integration of the technologies in their projects. Having running and up-to-date clusters require talended teams with architects and engineers to select the appropriate tool for the job and fit the configuration to your hardware. Because of this, businesses see a limited ROI from what they can derive from their data due to poor query performance, difficult to use tools, and bulky execution engines in Hadoop.
On the other hand, the on-premise model comes with its own set of challenges:
- Resources cannot be scaled independently
- Clusters are difficult to scale and upgrade
- Large upfront machine costs
Thus, companies have come to find that the problem with Apache Hadoop is the overall complexity of the environment as well as the complexity involved in responding to changing business requirements.
Skills
In the last years, more workloads and data have moved to the cloud, and most of the cloud providers offer their own managed services. Today, organizations leverage on the available managed services enriched with containers capabilities, to develop tailored data platform. The Apache Hadoop ecosystem tends to be forsaken and skills on Hadoop are now hard to find, and will be even harder in five years.
Community
Hadoop projects are gradually losing their contributors and communities are gradually turning to other open-source initiatives.
Technologies
In 2017, Apache Hadoop misses a huge turn: Kubernetes. YARN has many killer-features, the two top being a flexible resources scheduler based on various strategies, and other being the reservation system. YARN supports the notion of resource reservation via the ReservationSystem, a component that allows users to specify a profile of resources over-time and temporal constraints (e.g., deadlines), and reserve resources to ensure the predictable execution of important jobs. Useful for your nightly batches when you can estimate precisely your jobs. But YARN is complex, and create a simple Python job is overe laborate.
Design
But the main pain is HDFS. As the default storage layer in Apache Hadoop, HDFS still suffer from the small files problem. HDFS tries to fix this problem with the Federation feature. The prior HDFS architecture allows only a single namespace for the entire cluster. In that configuration, a single Namenode manages the namespace. HDFS Federation addresses this limitation by adding support for multiple Namenodes/namespaces to HDFS. But even if you can “split” the hierarchical tree of HDFS, you can still be faced to the small file problem.
Quality of Service (QoS)
Although Apache Hadoop, thanks to Yarn, makes it possible to isolate the workloads, the queries executed on the different endpoints can affect a cluster. Apache Hadoop introduced QoS (Quality of Service) features, such as request throttling, which controls the rate at which requests are processed by a cluster. The cluster generally treats all requests equally. Throttling features can be used to specifically limit maximum throughput, bandwidth, or estimate the load induced by this request to ensure deterministic behavior and controlled impact on the cluster. The limit can be applied to a specific query or, alternatively, to queries directed at data items, such as tables or a namespace. Demand throttling is an effective and useful technique for managing multiple workloads, or even multi-tenant workloads on a single cluster. Clusters are generally used in a multi-tenant environment where many organizations/teams used a shared capacity. QoS is although partially implemented, and a single team on a shared cluster kneel the entire cluster.
As a result, many Hadoop customers are looking at more cost-effective, less complex solutions. But it is difficult to find simple alternatives requiring few modifications for Apache Hadoop-based projects. Many are now considering migrating to BDaaS (BigData as a Service) solutions.
Steps to Migrate
In case, you don’t want or can’t to move away from all of the Hadoop tools, many alternatives can be considered:
- Google Dataproc
- AWS EMR
- Azure HDInsight
- CDP Hybrid Cloud
- Qubole
- Graal Platform
- Etc…
Most of these solutions can be used to run your existing jobs with minimal alteration. All these solutions involve managing clusters, Apache Hadoop is “partially” managed and critical configurations must still be maintained. Consider Graal Platform if you want a straightforward solution with no clusters to setup or maintain and a ready-to-use solution.
Below are some of the recommended steps for migrating your workflows from an Apache Hadoop cluster to Graal Platform:
1| Move Your Data First
Firstly, you have to move your data into a cloud storage like AWS S3 or Azure DataLake Gen2. AWS S3 and Azure DataLake Gen2 can be used to replace Apache HDFS without any modification in your projects. Many tools can be used to move your data from HDFS to these cloud storage, starting from a CLI like DistCp or simple ETL jobs.
2| And it’s done!
Graal Platform can be used as a huge Apache Hadoop cluster. We reimplemented the Apache YARN RPC protocol to guarantee the portability of your Apache Hadoop-based projects. Apache Spark, Apache Sqoop, Apache Hive and all frameworks based on Apache YARN will work in the same way as on your current clusters. To move your Apache Hadoop stack, you don’t have to create ephemeral clusters or build specialised infrastructures on your cloud providers. Simply download the *-site.xml configurations from the console or via the API, and and you are already done!
Conclusion
Migrating from Hadoop to Graal Platform offers a number of benefits, such as built-in support for Hadoop, managed hardware and configuration, simplified version management and flexible job configuration. If you have plan to shut down your Apache Hadoop clusters and want to migrate fast with minimal effort, Graal Platform is the perfect solution for you!