
Kubernetes for (Big)Data
Defining the correct architecture for deploying big data software in production systems is one of the most difficult aspects of designing big data solutions. Big data systems are large-scale applications that handle online and batch data that is growing exponentially. To bridge the gap between the vast volumes of data to be processed, software applications, and low-level infrastructure (on-premise or cloud-based), a scalable, reliable, secure, and easy to administer platform is required.
Kubernetes is one of the greatest options for deploying apps on large-scale infrastructures. It is possible to handle all of the online and batch workloads required to feed analytics and machine learning applications using Kubernetes.
Hadoop vs Kubernetes
Apache Hadoop has long been the dominant framework for creating scalable and distributed applications in the big data environment. Hadoop’s popularity has dwindled as cloud computing and cloud-native applications have gained traction (although most cloud vendors like Azure, AWS and Cloudera still provide Hadoop services). Hadoop consists of three primary components: a resource management (YARN), a data storage layer (HDFS) and a computation paradigm (MapReduce). Modern technologies such as Kubernetes for resource management, Amazon S3 for storage, and Spark/Flink/Dask for distributed compute are replacing all Hadoop components. Furthermore, the majority of cloud providers offer their own computing solutions.
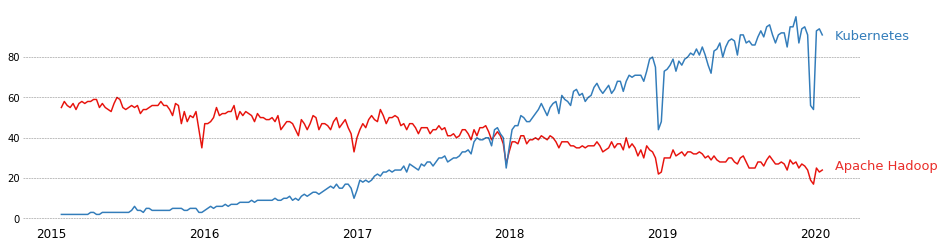 Google Trends comparison of Apache Hadoop and Kubernetes.
Google Trends comparison of Apache Hadoop and Kubernetes.
We must first establish that Hadoop and most other big data stacks do not have a “one-versus-all” relationship with Kubernetes. In fact, Hadoop can be run on Kubernetes. Hadoop, on the other hand, has been developed in a very different environment than we have now. It been created at a time when network latency was a big concern. Companies were obliged to build their own in-house data centers to avoid having to move enormous volumes of data around for data science and analytics purposes. However, large companies that want to have their own data centers will continue to use Hadoop, but adoption will probably remain low because of better alternatives.
Cloud storage providers and cloud-native solutions for executing huge computations off-premise are now dominating the landscape. Furthermore, many enterprises want to have their own private clouds on-premise. As a result, Hadoop, HDFS and other similar products have lost their traction in favor of newer, more flexible and eventually cutting-edge technologies like Kubernetes.
Kubernetes pros
Because of the scalability and extensibility of Kubernetes clusters, big data applications are good candidates for using the Kubernetes architecture. There have been several significant recent developments in the use of Kubernetes for big data. For example:
-
Apache Spark, the “poster child” of compute-heavy operations on large volumes of data, is working on adding the native Kubernetes scheduler to run Spark jobs.
-
Google just revealed that they would be using Kubernetes to schedule their Spark workloads instead of YARN.
-
Thousands of Kubernetes clusters have been deployed by eBay to manage their Hadoop AI/ML pipelines.
-
Isolation of resources guaranteed (CPU, RAM, disk, even GPU and network), which was possible but complex with Hadoop.
-
Isolation of dependencies
-
Ease of deployment, management and observability.
-
The big community of Kubernetes (with more than 3000 contributes on GitHub).
Kubernetes cons
Despite these multiple advantages, Kubernetes still has some major pain points when it comes to deploying massive big data stacks. For big data applications running on Kubernetes, the absence of persistent storage that can be shared between jobs is a huge concern because containers were built for short-lived, stateless apps. Other significant concerns include scheduling (Spark’s implementation is still in its early stages), security (Hadoop uses Kerberos as the basis for strong authentication and identity propagation for both user and services.), and networking.
Consider the case where node A is running a job that requires reading data stored in HDFS on a data node that is sitting on node B in the cluster. Unlike YARN, data is now sent via the network for computation purposes, this would dramatically increase network latency. While efforts are being made to address these data locality issues, Kubernetes still has a long way to go before it can truly be considered a viable and realistic alternative for deploying large data applications.
Nonetheless, the open-source community is working hard to resolve these difficulties so that Kubernetes may be used to deploy large data applications. Because of its inherent advantages such as robustness, scalability, and resource usage, Kubernetes is getting closer to being the de facto platform for distributed, big data applications every year.
Next technologies
The experience of using Kubernetes for data engineering have a lot of advantages, but also have multiple drawbacks such as setup complexity, resource management, priority management, observability, lineage, deployment and maintenance.
To handle these cons, new solutions were born in order to facilitate and accelerate the production of data projects for companies in all sectors.
This is the case of Graal Systems which provides a fully managed data platform to allows companies from different sectors to quickly implement solutions to the most difficult data problems and to accelerate and boost the implementation of data projects.
To go further, feel free to try Graal Platform!