Data integration is essential for modern businesses that want to make better strategic decisions and increase their competitive advantage. The main actions in data pipelines are one way to achieve this goal.
The growing need for data pipelines
As data volumes continue to grow at breakneck rates, businesses are using data pipelines to unleash the power of their data and respond to requirements faster.
According to IDC (International Data Corporation), by 2025, 88% to 97% of global data will not be stored. This means that in just a few years, data will be collected, processed and analyzed in memory and in real time. This prediction is just one of many reasons behind the growing need for scalable data pipelines.
-
Acceleration of data processing: The time allowed to process data is very short, and data quality is a major concern for senior managers. There is erroneous data everywhere, and often incomplete, outdated or incorrect. In this world driven by data, we can no longer afford to spend hours on tools like Excel to correct these errors.
-
The shortage of data engineers: Companies cannot stem the relentless flow of productivity demands, despite the shortage of qualified data scientists. It is therefore crucial to have intuitive data pipelines to exploit the data.
-
Difficulty keeping up with innovations: Many companies are held back by an old and rigid infrastructure, as well as by the skills and processes associated with it. As data volumes continue to grow and evolve, companies seek scalable data pipelines that can easily adapt to changing requirements.
Data in the pipeline
A typical business has tens of thousands of applications, databases, and other sources of information such as Excel spreadsheets and call logs. And all of this information needs to be shared between these data sources. The rise of new cloud and big data technologies has also contributed to data complexity, as stakeholders increase their demands. A data pipeline encompasses a series of actions that begin with ingesting all raw data from any source, quickly transforming it into actionable data.
The Journey Through the Data Pipeline
The data pipeline comprises the entire journey of data through a business. The four main actions that happens to data as it goes through the pipeline are:
-
Collecting or extracting raw data sets. Datasets can be pulled from an infinite number of sources. Data comes in a variety of formats, including database tables, filenames, topics (Kafka), queues (JMS), and file paths (HDFS) . At this stage, the data is neither structured nor classified. It’s a real mess of data, from which you can’t make any sense.
-
Data governance. Once the data is collected, companies need to build a discipline to organize the data. This discipline is called data governance. We start by linking the raw data to the context of the company so that it makes sense. We then control the quality of the data and the security of the data, before organizing them fully for mass consumption.
-
Data transformation. Data transformation consists of cleaning and converting data sets into the appropriate reporting formats. Unnecessary or invalid data must be eliminated and the remaining data is enriched according to a series of rules and regulations defined by the data needs of your company. Standards ensuring data quality and accessibility during this step should include:
-
Standardization — Definition of important data and how it will be formatted and stored.
-
Deduplication — Reporting of duplicates to data managers. Exclusion and/or deletion of redundant data.
-
Checking — Run automated checks to compare similar data such as transaction time or access tracking. Verification tasks help eliminate unusable data and flag anomalies in systems, applications, or data.
-
Sorting— Optimizing efficiency by grouping and storing items such as raw data, audio or multimedia data, as well as other objects in the within categories. The transformation rules condition the categorization of each object and its next destination. These transformation steps reduce what was once a mass of unusable material to quality data.
-
Data sharing. Now that it is transformed and trusted, the data is finally ready to be shared. Everyone is eager to have this data, which is often sent to a cloud data warehouse or an endpoint application.
-
When it comes to data processing and integration, time is a luxury that companies can no longer afford. The goal of any data pipeline is to integrate data to deliver actionable insights to consumers, in near real time. Developing a data pipeline should be a repeatable process that can handle batch or streaming jobs, and be compatible with the cloud or a big data platform of your choice, now and in the future.
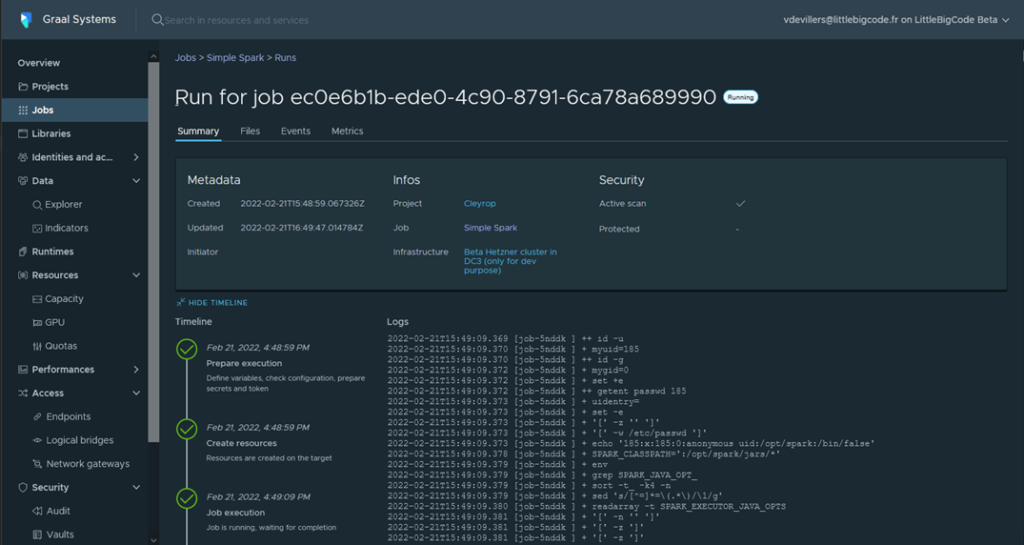
Build a datapipeline using Graal Platform
Graal Systems offers its Graal Data Platfom to automate and simplify these processes for simple and fast data integrations. In any format and from any source. Graal Platform also includes advanced security features, with many connectors, and a set of data management tools to ensure a smooth integration from start to finish.
-
Connect to the Graal Platform console (https://console.beta.graal.systems/)
-
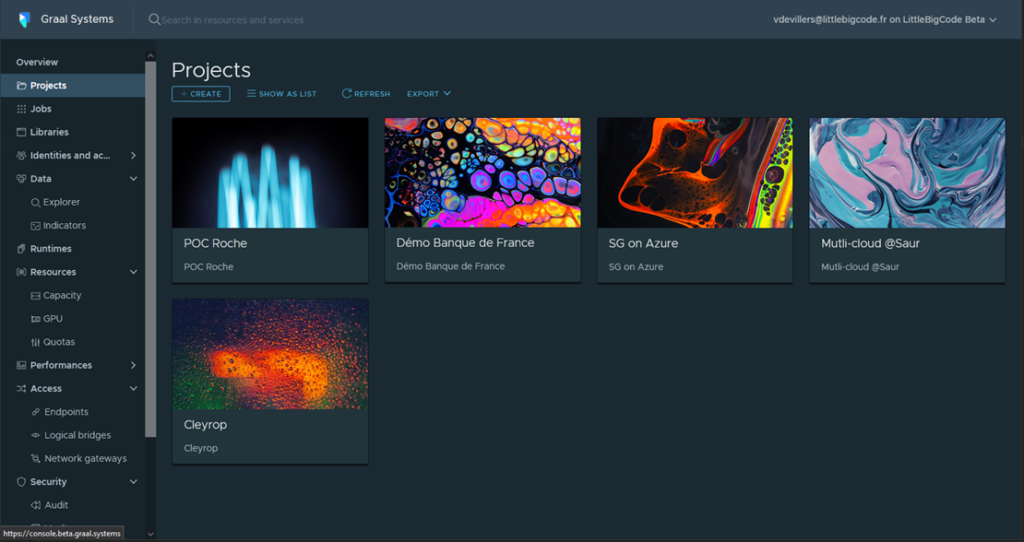
On the main Admin console page, select Projects and create a new project
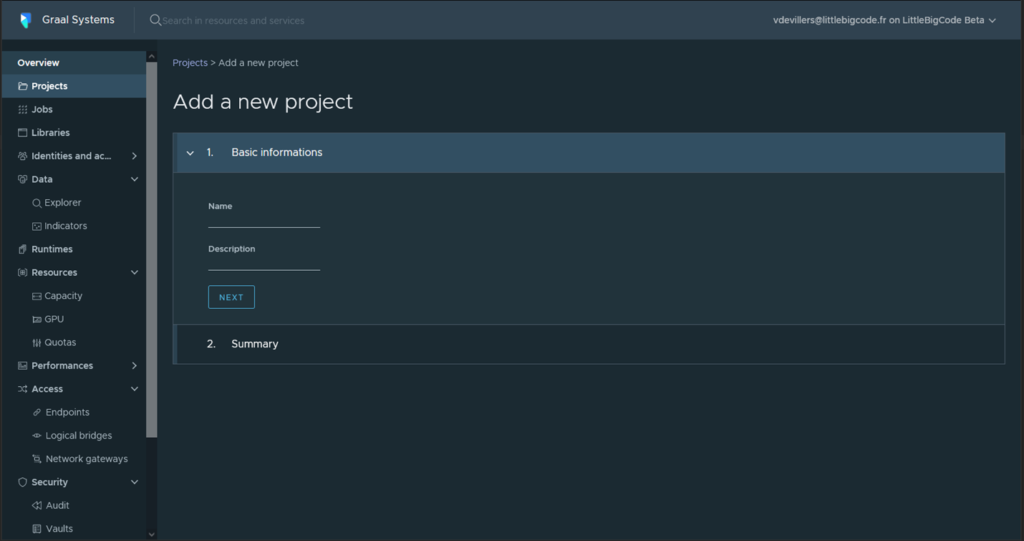
-
Create a new job for a project: Spark, Tensorflow, Beam, Flink …
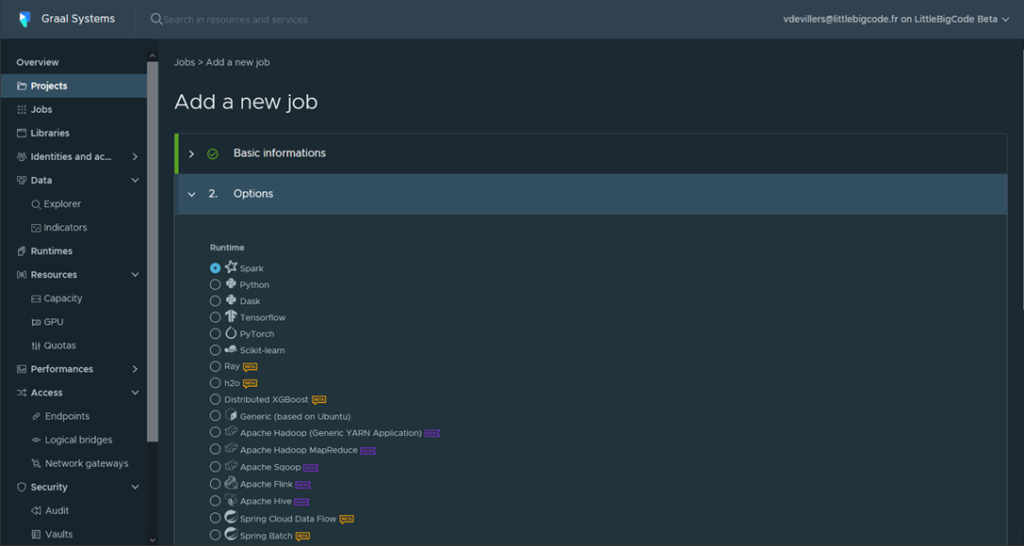
-
Run your job on one or more infrastructures
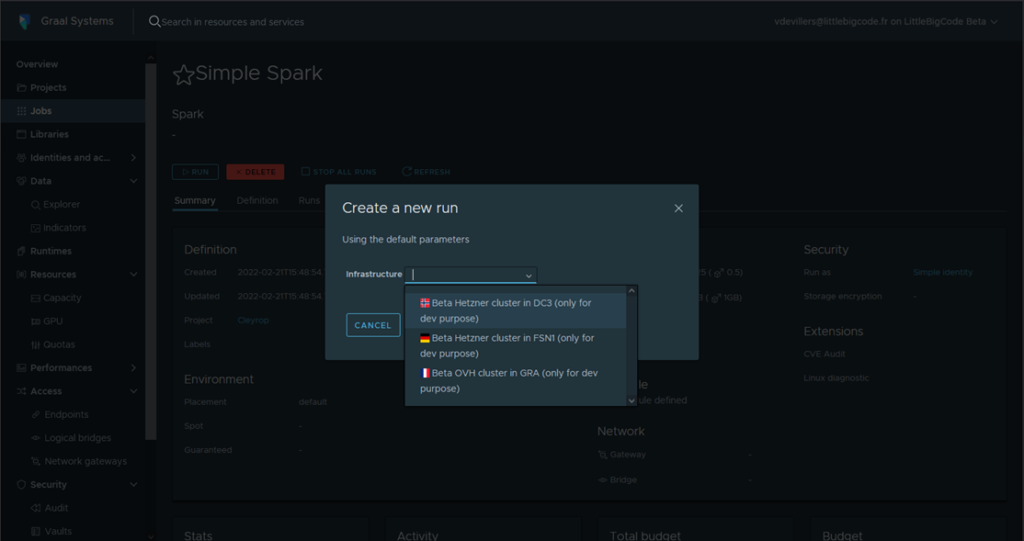
-
Follow the execution of your job, the events and the associated logs in real time